
Today I shall conduct a very basic attempt at topic modeling CBC News dataset I have scraped from Web. Topic modeling is the statistical modeling process in which we try uncover abstract “topics” based on the collection of documents and words. I will firstly scrap data from CBC News Website and then discuss a standard topic modeling technique known as Latent Dirichlet Allocation (LDA).
We first import some basic library, then we construct the CBC News website. We have created a function to do it. The Company and City are the places we are looking for. In this case, we will take look at Canada Toronto’s CBC News.

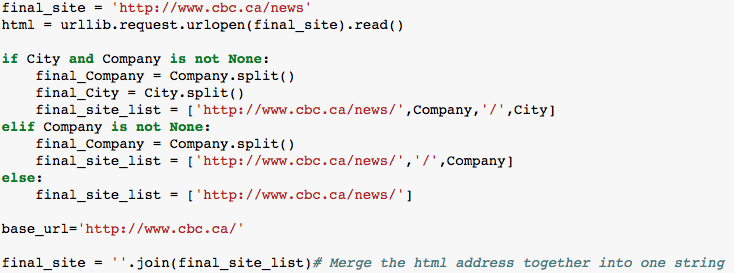
Next step is to use urllib.request to open the URL we have just created, and use BeautifulSoup to parse HTML into our Jupyter Notebook. The reason why we use try … except is because there might be some bugs in HTML and it might return the error. Then we use find to find the specific place where we take a look at.

Then we will use PageElement.extract() removes a tag or string from the tree. And use find all and get to obtain hyperlinks. Once we get the hyperlinks, we again will use urllib.request to open each link and use Beautiful Soup to translate the HTML to our Notebook. Then we use the chunk to fix the spacing issue and encode it to ‘utf-8’. After that, we need to decode it as well.
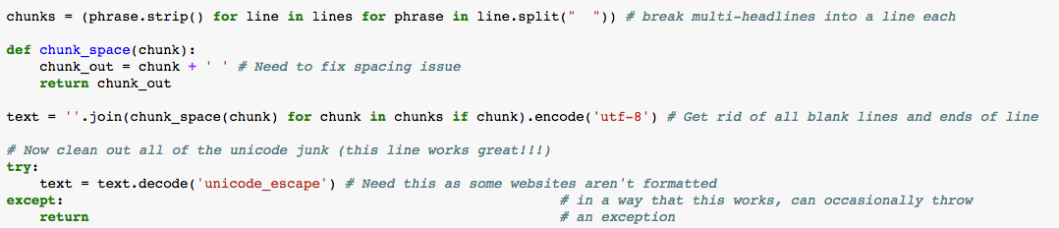
Next step is to clean the web data. We will delete all the stopwords.words(‘english’) such as ‘a, is, the…’. Then we use string.punctuation to delete all the punctuations. Moreover, we have used WordNetLemmatizer() to combine variants of words into a single parent word that still conveys the same meaning. The last but not the least, since in the text we have spelling errors, we need to use enchant to check the spelling of words and to get suggestions for misspelled words. The last step of web scraping is using sleep to prevent overwhelming server.

In the end, we have obtained the text something like this.

The next part of this project is to create the dictionary of our corpus a collection of written texts.


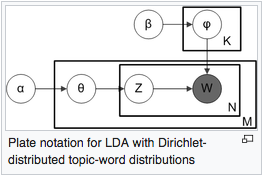
The last significant part is topic modeling LDA. Latent Dirichlet Allocation – Probabilistic, generative model which allows sets of observations to be explained by assigning weights to words in a corpus, where each topic will assign different probability weights to each word. I have paste general process in below form Wikipedia from https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation.


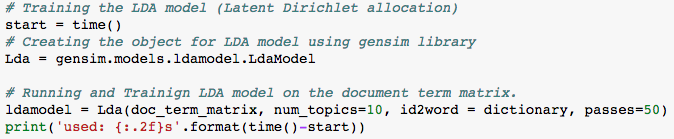
To training the LDA model, we use gensim library fitted the model and training the document term matrix.

Then we use Word Cloud to visualize the topics. We have to use alice.png to create a mask then generate this word cloud.



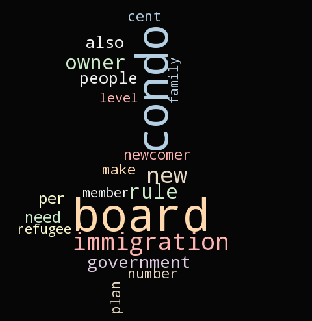
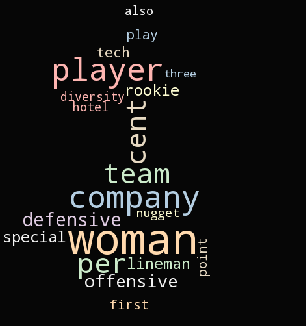

In the end, we have created Intertopic Distance Map by using pyLDAvis.gensim.
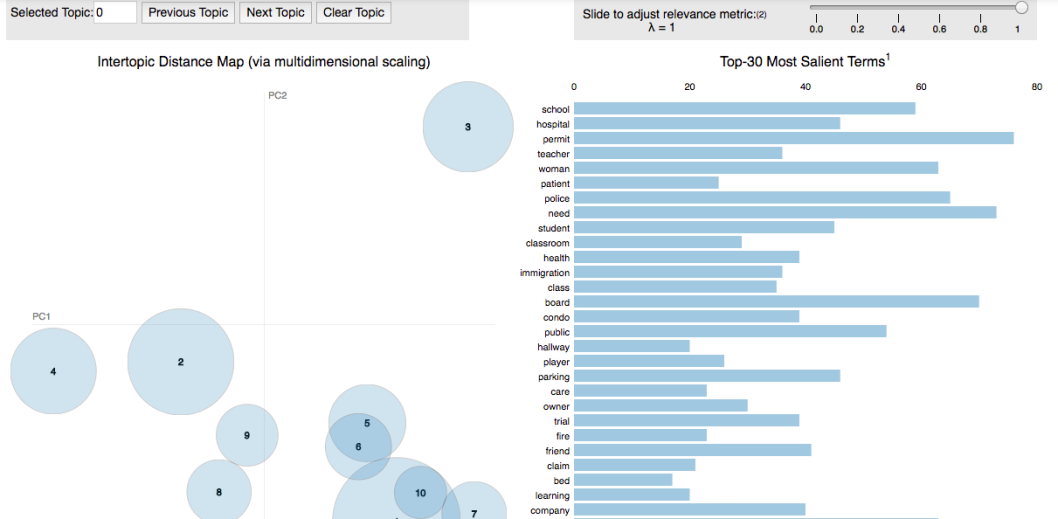

I like the topic. however, what’s the conclusion ?
LikeLike
Topic models provide a simple way to analyze large volumes of unlabeled text. A “topic” consists of a cluster of words that frequently occur together. Using contextual clues, topic models can connect words with similar meanings and distinguish between uses of words with multiple meanings.
So in the end, my result is to find out the “topic” of each CBC News in Toronto.
LikeLike